


Breaking down Machine Learning Types in Simple Words
Understanding Supervised, Unsupervised and Reinforcement Learning Models with Examples

Hey this Darshana! 👋👋
Welcome back to my AI series, where I break down complex concepts into simple, relatable examples.
In the previous article we explored the Basics of Machine Learning using a Movie Recommendation System as an example. If you haven’t checked it out yet, you can read it here!
In this article we will dive deeper into the world of Machine Learning. We’ll explore the types of Machine Learning models with relatable examples, and as promised, we will keep it jargon free as much as possible so it’s easy to understand and engaging.
A short recap on whats Machine Learning (ML)
ML is a subset of artificial intelligence that enables systems to learn from data and improve their performance over time without being explicitly programmed.
Basically, you feed the system with datasets, and it learns to identify patterns within the data. Then, when it encounters similar but previously unseen data, it can recognize those patterns and provide insights.
However, this is a broad generalization of how ML works. As we dive deeper, we’ll see that not all ML models function the same way. They differ in the types of datasets they learn from and the algorithms they use. We’ll explore these differences in detail in this article.
Types of Machine Learning
ML is broadly categorized into three types:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
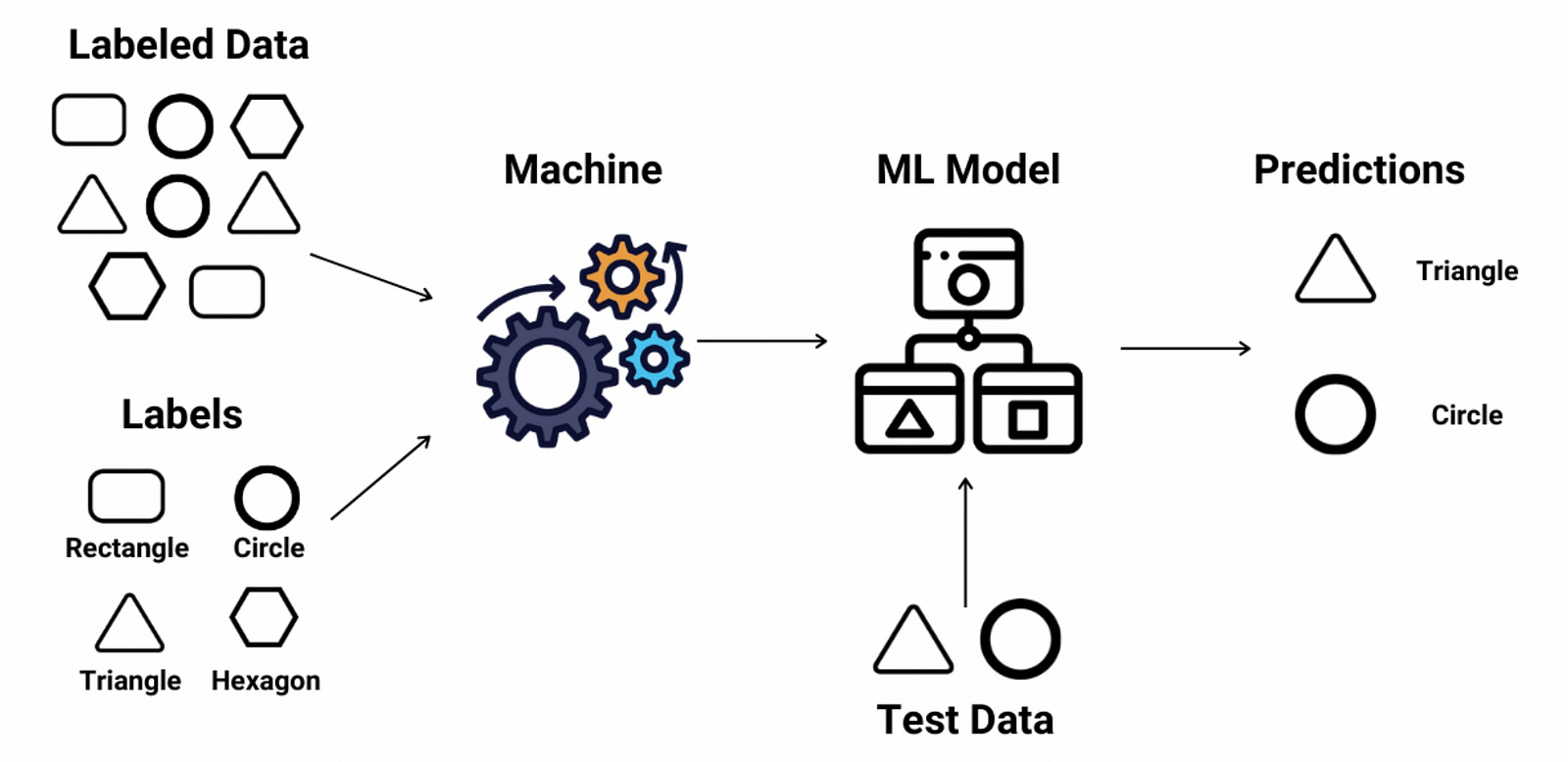
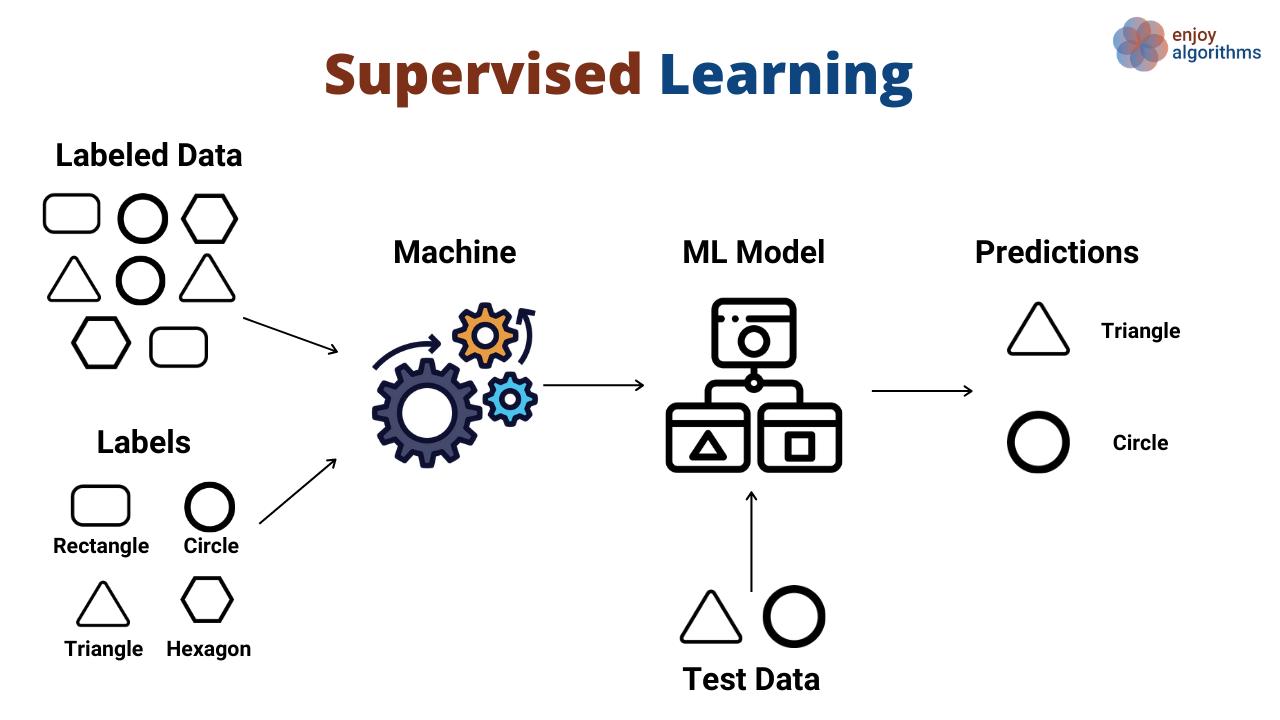
Supervised Learning: Learning with Guidance
Imagine you’re learning a new subject, and your teacher provides you with a list of example questions along with the correct answers. You go through these examples to understand the types of questions and the expected answers. When you take the main test, the questions might be different, but because you’ve practiced with the examples, you’ll be able to apply the same analysis and find the solution.
This is the essence of Supervised Learning.
In supervised learning, the machine learns from data that is already labeled. That means the data comes with both input (features) and output (labels). The algorithm looks at these examples and tries to learn the relationship between them. The goal is to predict the output for new, unseen data.
So how does this work in real time? Lets understand this with a simple example where the model classifies the emails as spam or not spam.
Training Data: First we feed the system with training data. So in our case, we label the emails as spam and not spam and input the data set to the model.
Learning: The model learns the features or patterns that distinguish spam emails from non-spam ones. For example, it might learn that the emails listed as spam usually have unknown senders, it might contain text like “free” or it might have excessive exclamation points. Based on these patterns, it can classify an email as spam or not spam.
Prediction: Once trained, the model can predict whether a new email is spam or not.
Another common example for supervised learning model is House Price Prediction — given features like square footage, number of bedrooms, etc., the model predicts the price of a house.
Unsupervised Learning: Discovering Patterns on Your Own
While solving puzzles, you’re usually given the final image as a clue and start joining the pieces to complete the puzzle. Now, imagine you’re not given the final picture. You only have a box of pieces and must figure out the patterns along the way to arrive at the solution. This is exactly how unsupervised learning works.
In unsupervised learning, the data isn’t labeled. Instead of being provided with answers, the machine searches for patterns or groupings within the data. It’s all about uncovering the hidden structure in the information.
So how does this work in real time? Lets understand this with a simple example where the model is provided with customer information.
Input Data: The algorithm is given a set of data without labels (e.g., a collection of customer information).
2. Learning: The model tries to find patterns, like grouping customers with similar behaviors or characteristics.
3. Output: The algorithm identifies clusters or groups.
Based on the kind of customer information, the model can come up with various insights. For example, customer information can be grouped based on behaviour, for targeted marketing.

Reinforcement Learning: Learning by Doing
Reinforcement learning is like teaching a child to play a game — trial, error, and rewards guide the learning process.
In reinforcement learning, the machine learns by interacting with its environment and receiving feedback in the form of rewards or penalties. The goal is for the machine to learn a strategy (called a “policy”) that maximizes the cumulative reward over time.
So how does this work?
Agent: The learner (the machine).
Environment: The world the agent interacts with (e.g., a game or a robot’s surroundings).
Actions: The decisions the agent can make (e.g., moving a robot or choosing a move in a game).
Rewards: Positive or negative feedback based on the action taken (e.g., winning a game or losing).
A common example of reinforcement learning is self-driving cars. The car learns to navigate roads by receiving rewards for safe driving and penalties for mistakes. For instance, each time the car hits a barrier or makes an incorrect move, it gets a penalty. The model learns to avoid such obstacles or mistakes in the future. On the other hand, when the car makes a correct move or turn, it is rewarded. Over time, the model learns what to avoid and how to drive safely.
Its just like teaching a puppy — you give it treats for good behavior and withhold treats for bad behavior, helping it learn what is expected over time.

Challenges in Machine Learning
While machine learning sounds like magic, it’s not without its challenges.
Overfitting vs. Underfitting
Overfitting is like “mugging up” the training data rather than understanding the underlying patterns. The model memorizes specific details and noise from the training data, which may not be useful for generalizing to new, unseen data.
So instead of learning the trends or relationships from the training data that can be applied to the new data sets, it becomes too focused on specifics, making it less effective when faced with new examples.
Underfitting occurs when the model is too simple to learn the underlying patterns of the data, resulting in poor performance on both training and new data.
There are some challenges that arose with the growing demand for machine learning applications, particularly in scenarios where labeled data is scarce or expensive to obtain. For instance, identifying all types of spam emails and creating a labeled list can be both time-consuming and costly.
Additionally, for most practical applications, there is often a large amount of unlabeled data, but unsupervised learning doesn’t offer the same level of accuracy as supervised learning. To address these challenges, a middle ground approach was introduced.
To solve these challenges, Semi supervised learning was introduced.
Semi-Supervised Learning
Semi-Supervised Learning sits somewhere between supervised and unsupervised learning. It’s like being given a few examples with the correct answers but also exploring and learning from unlabeled data.
In semi-supervised learning, the machine is provided with a small amount of labeled data and a large amount of unlabeled data. The model can leverage both to learn better and make more accurate predictions.
Labeled Data: The machine is given a small set of data with known outputs (labels).
Unlabeled Data: Alongside labeled data, there’s a larger pool of data without labels.
Learning: The model combines both labeled and unlabeled data to learn patterns. The labeled data acts as a guide, while the unlabeled data helps the model generalize better.
It’s like learning a language with a few translated phrases but spending most of your time listening to people speaking in that language. You learn from the examples and gradually pick up patterns from context.

{kind=link}
{kind=link}
{kind=link}
Takeaway
Machine learning is a powerful tool for solving a variety of problems, but understanding the different types — supervised, unsupervised, and reinforcement learning — helps you choose the right approach for your data and task. By learning how to apply these techniques, you’ll be able to build smarter systems that can predict, classify, and even make decisions on their own.
Stay tuned for the next article in the series, where we’ll explore real-world applications of ML and how businesses and industries are using it to drive innovation.
If you found this article valuable and want to join in this journey with me, subscribe to my Substack channel.
Feel free to share this article with anyone you think would benefit from it. Your support means the world to me, and I look forward to bringing you more insightful content.