


Breaking Down Machine Learning: Key Terms and Concepts You Need to Know
Making Sense of ML Terminologies through a Movie Recommendation System

Hey, this is Darshana! Welcome back to my AI series, where I break down complex concepts into simple, relatable examples. If you missed my previous article, you can find it here. In this blog, we will be exploring Machine Learning (ML) — one of the most important pieces of the AI puzzle.
I’m diving into the AI world, and I want you to join me as we uncover its potential and opportunities.
Feel free to share your thoughts or suggest topics you’d like me to explore or research.
By the end of this article, you’ll have answers to some of the most common questions about Machine Learning:
How does ML fit into AI?
What exactly is ML?
How is it different from traditional programming?
And finally, we’ll get familiar with some common ML jargons/terms, such as datasets, features, models, algorithms, training, validation, inference, and deployment.
Get ready to dive into some easy-to-understand explanations, supported by examples you can relate to.
How Does ML Fit into AI?
AI is like the brain, and Machine Learning (ML) provides a way to help the brain learn and improve. ML behaves like a neuron, the fundamental part of the brain, that helps it learn and adapt to new experiences and data.
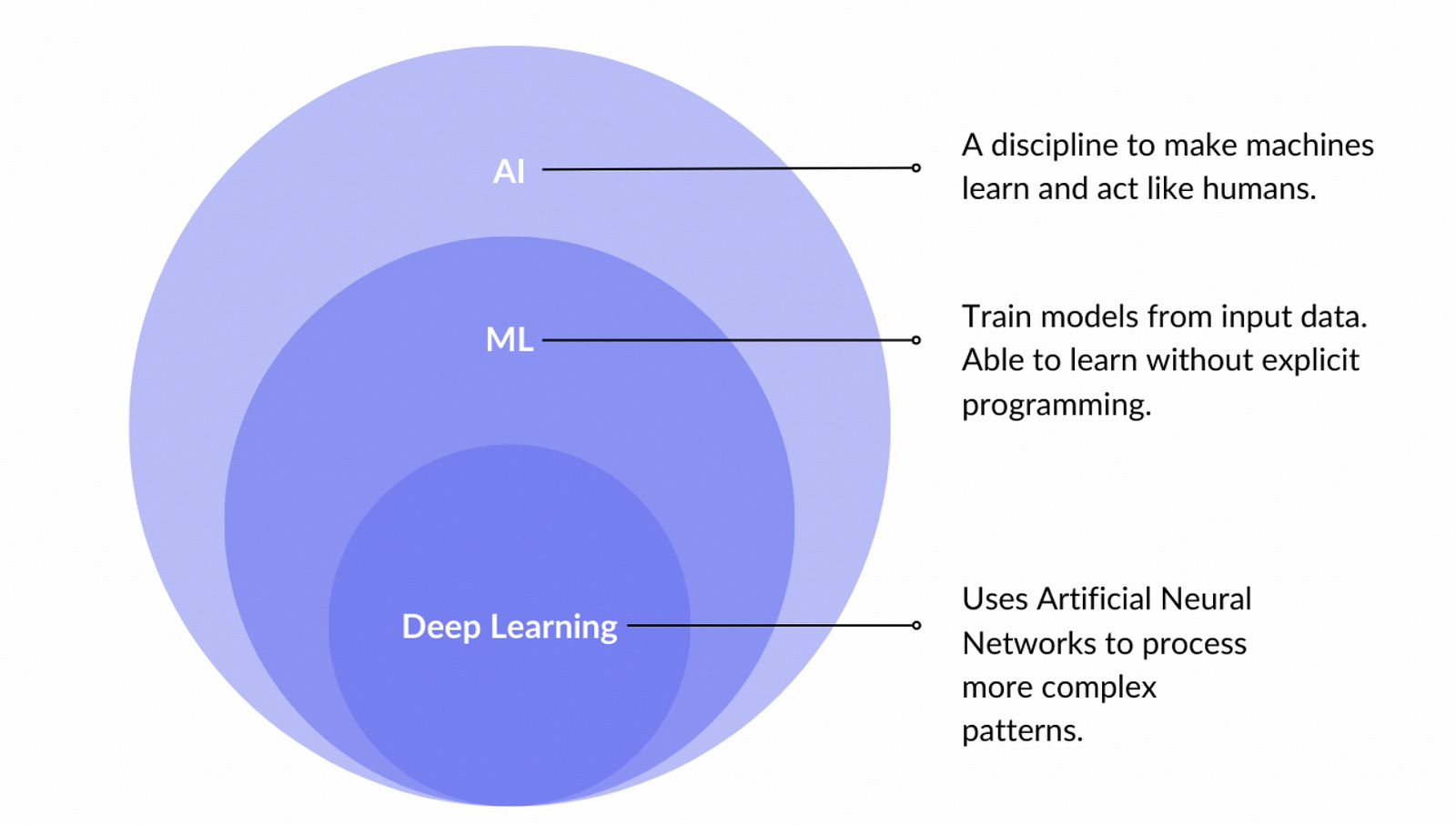
While AI is the broad concept of making machines “smart,” ML is the strategy we often use to make that happen.
Deep learning is a subset of machine learning that uses neural networks. More on this in the forthecoming articles.
Imagine teaching a toddler to recognize a cat. You show pictures of cats and after enough examples, the toddler starts recognizing cats independently. That’s ML — machines learning patterns from data.
Machine Learning Identifies patterns in data and uses those patterns to make predictions and decisions. The key idea behind ML is that the more data a system has, the better it can learn. Its like practice makes perfect.
What is Machine Learning?
At its core, ML is about creating systems that improve automatically through experience. Instead of writing detailed rules for every situation, we provide data, let the machine find patterns, and build its own “rules.”
For example, if we wanted a machine to predict house prices, we’d give it data like size, location, and age of houses (inputs) along with their prices (outputs). The machine then creates a relationship between the inputs and outputs and makes predictions.
For example, a linear relationship would be something like an increase in the area of the house (per square foot) resulting in an increase in the house price. On a graph, this would be a straight line indicating a linear relationship.
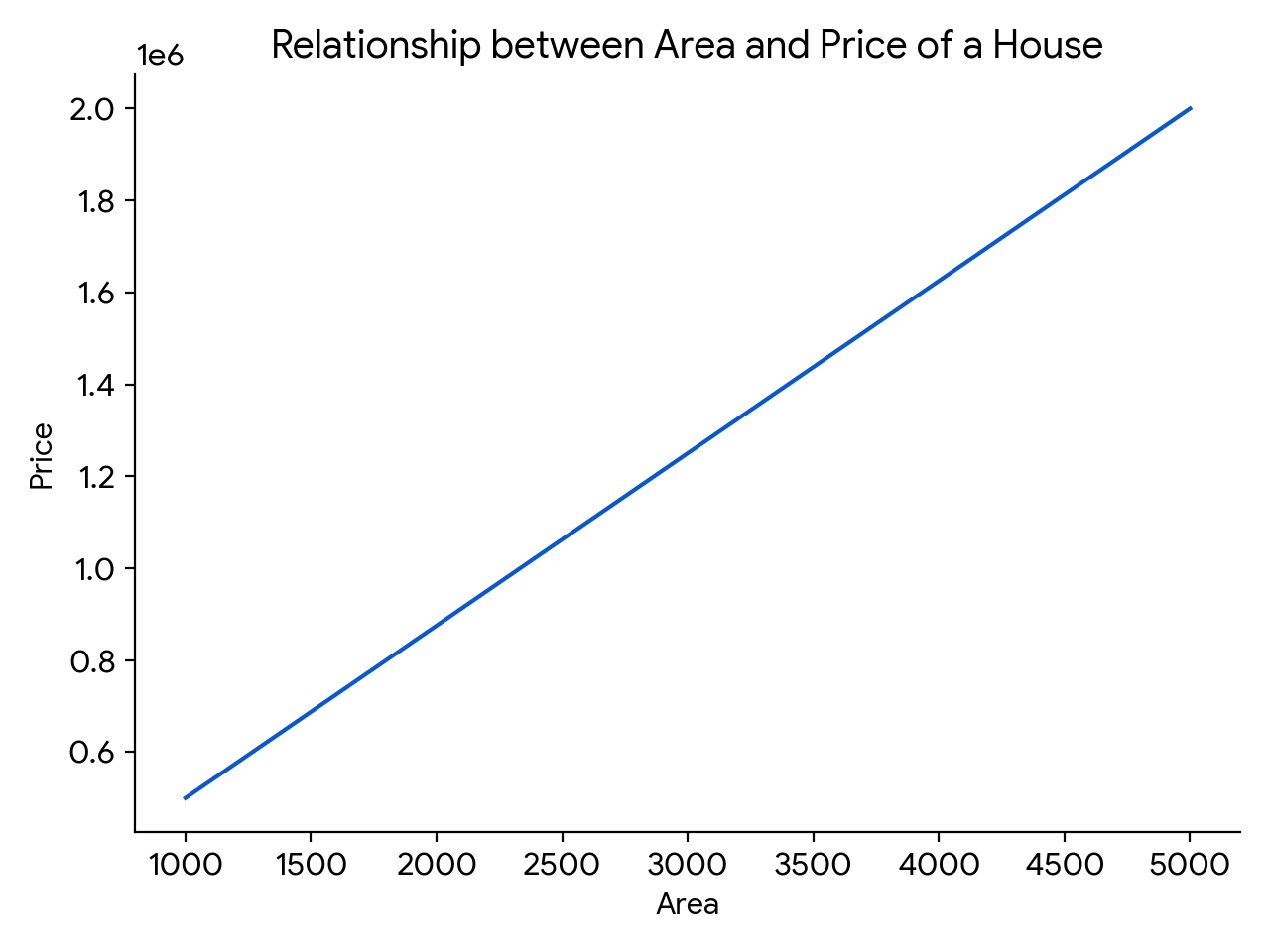
However, this relationship involves just two parameters. In real-time, ML takes into account multiple parameters, discovers relationships among them, and provides predictions.
How Does ML Differ from Traditional Programming?
In traditional programming, you tell the computer exactly what to do: step-by-step instructions like a recipe.
In ML, it’s more like baking without a recipe. You hand over ingredients (data) and let the machine figure out how to make something delicious.
For instance:
Traditional programming: “If the height is more than 5 feet, print ‘Tall’.”
ML approach: Feed the machine hundreds of examples of people’s heights and labels (“Tall” or “Not Tall”). The machine learns to predict “Tall” for new heights.
Understanding ML Terms
These terms, in a broad sense, describe the steps through which the entire ML process works in action. We’ll understand this through an example.
Example: Movie Recommendation System
1. The Dataset: The Starting Point
The process begins with collecting data. For a movie recommendation system, we need a dataset. This dataset could consist of user preferences (what movies they’ve watched) and movie details (genres, ratings, actors, etc.). The dataset might look like this:

Features refer to the properties or characteristics that describe each record. In this case, the User ID and Movie ID are features, as they describe the user and the movie.
Labels refer to the values that the model is trying to predict or classify. In this case, the Rating is the label, as it’s the value the model would predict based on the features (User ID and Movie ID).
2. The Algorithm
Now that we have our dataset, we need an algorithm to make sense of it. In this case, let’s say we use collaborative filtering which is a popular algorithm for recommendation systems.
The algorithm looks for patterns in user behavior — if two users rate movies similarly, they might like similar films in the future. Think of the algorithm as a recipe that tells the machine how to match users to movies based on their past behavior.
3. Training
Once we have our algorithm, it’s time to start training the model. Training is where the magic happens: the algorithm learns patterns in the data. In the case of our movie recommender, the algorithm will look at ratings across users and movies and begin to identify which movies tend to be liked by similar users.
For example, if User 1 and User 2 both rated action movies highly, the model will learn that they share similar tastes in action movies, so it will recommend more action films to them in the future.
During training, the model tries different “recipes” (or algorithms) and adjusts based on the data it learns.
4. Validation
Before we start using the movie recommendation on the real world cases, we need to make sure it works well. This is where validation comes in. We take a separate set of data (movies and ratings that the model has never seen before) and test how accurately the model predicts user preferences.
We might take a movie like “The Matrix” and check if the model recommends it to users who liked other action movies. If the model does well with this new data, then we know it’s good to go!
5. Inference
Once the model passes the validation stage, it’s time for inference — this is where the magic really happens. Now, the system can start recommending movies! For a new user or after a user watches a movie, the model will infer what movies they might like next based on what it learned from previous users. If you’ve watched “Inception,” the model might recommend “The Matrix” based on the patterns it has learned.
This step is when the model is actually being used to make predictions or decisions in real-time.
6. Deployment: Going Live
Now that the model is making predictions with reasonable accuracy, it’s time to deploy it. We push it out into the world — on a platform like Netflix, Hulu, or a custom movie recommendation app. When users sign up and start watching movies, the system is continuously making predictions and providing recommendations. This is when the model is truly working in the real world.
In summary, the following steps are typically followed in ML use cases:
Dataset: Data collection begins, with features (movie details) and labels (ratings).
Algorithm: We choose an algorithm (like collaborative filtering) to make sense of the data.
Training: The model learns patterns from the dataset using the chosen algorithm.
Validation: We test the model on unseen data to ensure it works well and generalizes.
Inference: Once trained and validated, the model makes predictions (recommends movies).
Deployment: Finally, we deploy the model for real-world use, where it continues to make predictions for users.
Machine learning might sound like magic, but it’s just math and logic wrapped in algorithms. By breaking it down, I hope this article helps you understand ML and its role in AI.
Next Stop: In the next article, we’ll dive into ML’s types — supervised, unsupervised, and reinforcement learning. Until then, let me know your thoughts or any AI/ML topics you’d like simplified.
If you found this article valuable and want to join in this journey with me, please subscribe to my Substack channel.
Feel free to share this article with anyone you think would benefit from it. Your support means the world to me, and I look forward to bringing you more insightful content .